시작하기
BlockAI에서 블록 연결을 통해 AI를 개발할 수 있습니다. 이 가이드에서 BlockAI 프로젝트를 만드는 법 및 사용자 인터페이스에 대해 알아보실 수 있습니다.
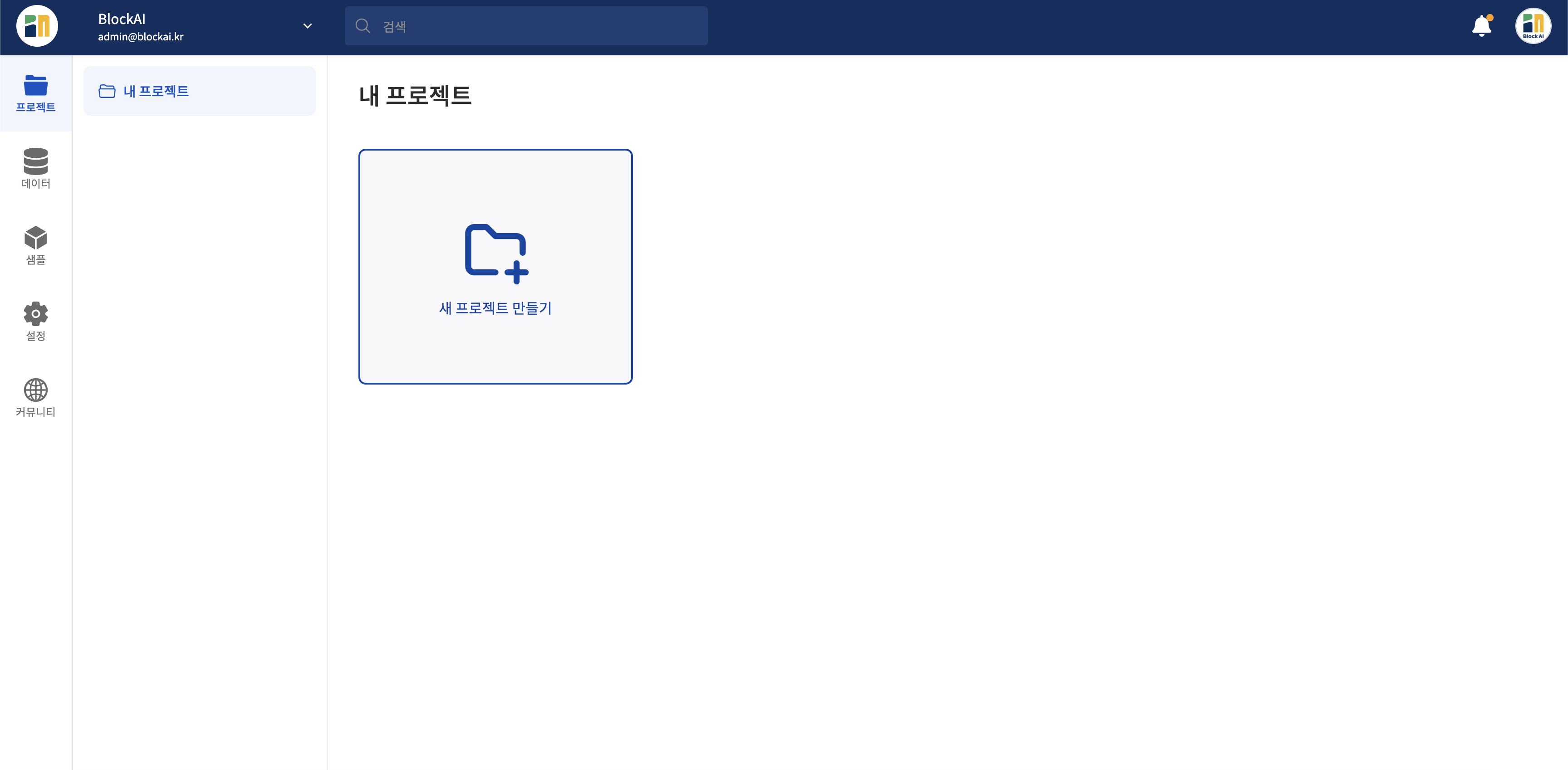
프로젝트 만들기
내 작업공간으로 이동해 새 프로젝트 만들기 버튼을 클릭하면 프로젝트를 만들 수 있습니다.
프로젝트 정보 입력
프로젝트를 만들기 위해 정보를 입력합니다. 각 입력값은 아래 그림과 함께 설명을 참고해 주세요.
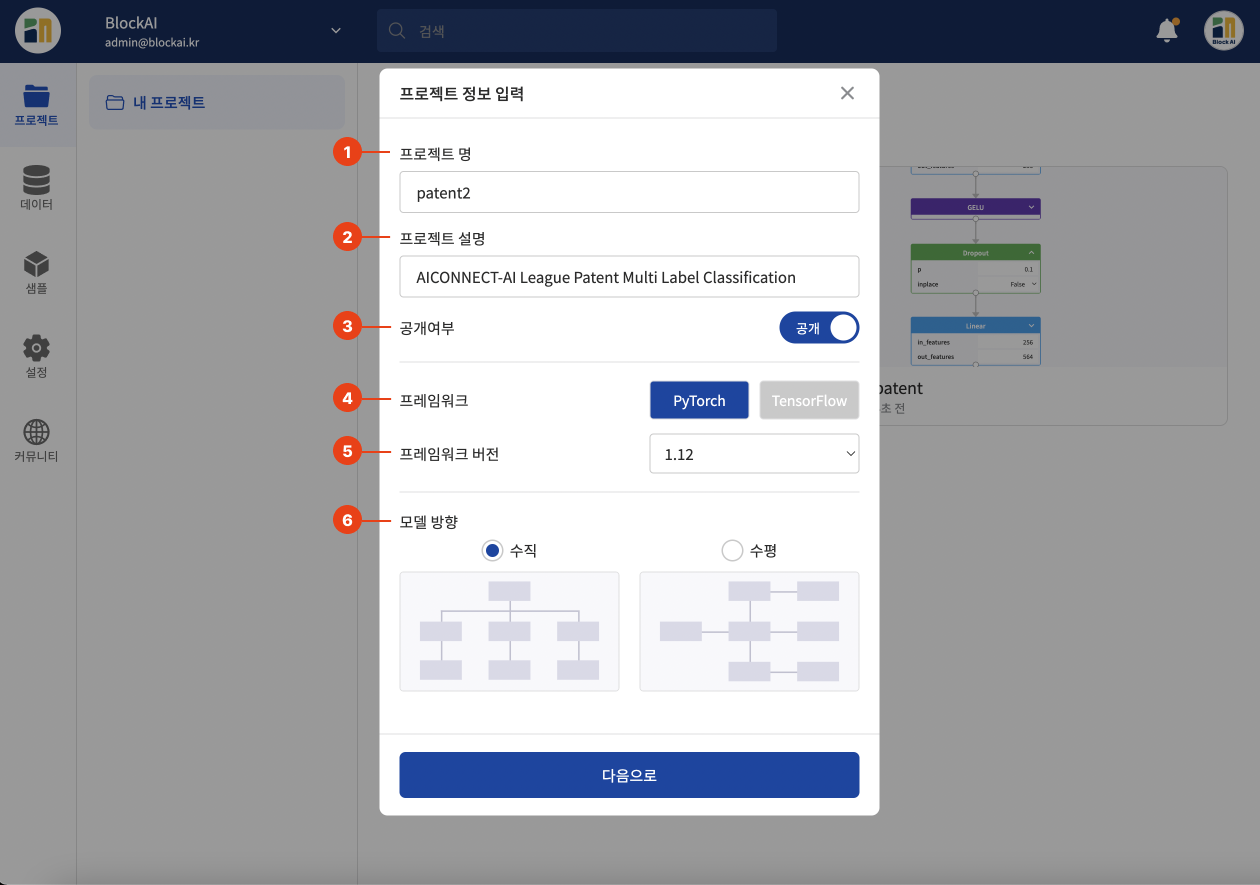
| 1 | 프로젝트 명 | 프로젝트 이름을 입력합니다. 프로젝트 이름은 2-50자의 영문, 숫자, -, _의 조합으로 이루어져야 합니다. |
| 2 | 프로젝트 설명 | 프로젝트를 간단하게 설명합니다. 최대 100자까지 입력 가능합니다. |
| 3 | 공개여부 | 프로젝트 공개 여부를 설정합니다. 공개로 설정하면 커뮤니티에 내 프로젝트가 검색됩니다. |
| 4 | 프레임워크 | 사용할 프레임워크를 선택합니다. 한번 선택하면 바꿀 수 없습니다. |
| 5 | 프레임워크 버전 | 선택한 프레임워크에 대한 버전을 선택합니다. |
| 6 | 모델 방향 | 선택한 모델 방향에 따라 프로젝트 생성 후 블록 연결 시, 블록 연결 방향이 결정됩니다. |
Hyper parameter 입력
프로젝트에 적용될 Hyper parameter를 입력합니다. 각 입력값은 아래 그림과 함께 설명을 참고해 주세요. 입력이 끝나고 프로젝트 만들기 버튼을 클릭하면 프로젝트가 만들어지고 모델 개발 페이지로 이동합니다.
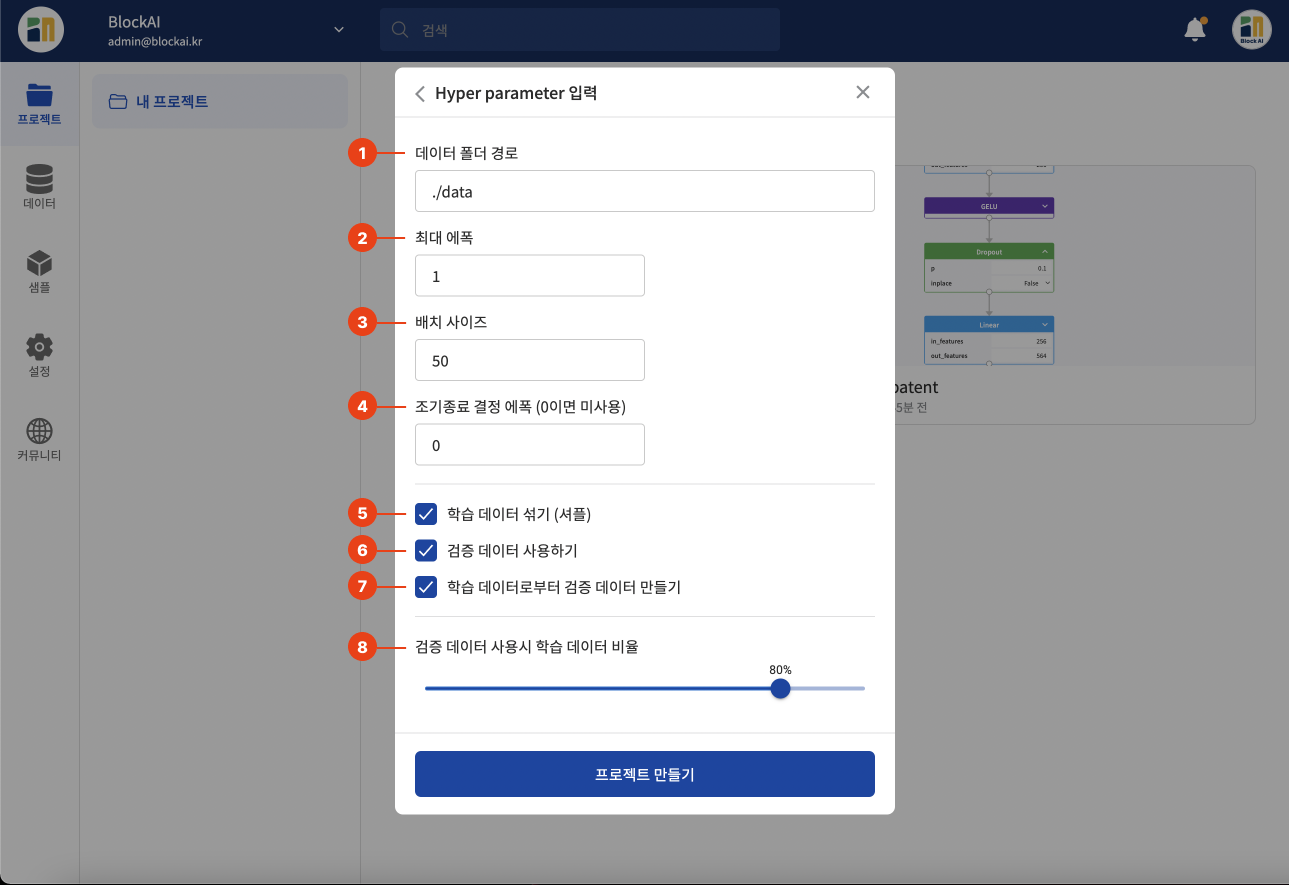
| 1 | 데이터 폴더 경로 | 데이터를 넣고 사용하실 경로를 입력해주세요. |
| 2 | 최대 에폭 | 학습할 에폭을 입력해주세요. |
| 3 | 배치 사이즈 | 배치 사이즈(Batch size)를 입력해주세요. |
| 4 | 조기종료 결정 에폭 | 오버피팅 방지를 위해 조기종료(Early stop)을 사용하실 경우 오버피팅을 판단할 에폭 수를 입력해주세요. |
| 5 | 학습 데이터 섞기 | 학습 데이터 셔플(Shuffle)이 필요한 경우 체크해주세요. |
| 6 | 검증 데이터 사용하기 | 검증 데이터를 사용하실 경우 체크해주세요. |
| 7 | 학습 데이터로부터 검증 데이터 만들기 | 검증 데이터가 없는 상태이지만 학습 데이터로부터 검증 데이터를 만들어서 사용하시려면 체크해주세요. |
| 8 | 검증 데이터 사용시 학습 데이터 비율 | 학습 데이터:검증 데이터의 비율을 선택해주세요. |
모델 개발 페이지의 구조
프로젝트를 생성하면 모델 개발 페이지로 이동됩니다. 이 페이지에서 블록을 연결하고, 데이터를 설정해 모델을 개발할수 있습니다. 페이지는 크게 좌측, 우측, 가운데로 구성됩니다.
좌측 영역은 모델 구현에 필요한 블록들이 나열되어있습니다. 각 메뉴는 Data, Layer, Activation, Loss, Operation, Optimizer, Huggingface로 구성되어 있고, 메뉴 클릭시 연관된 블록들이 화면에 나열됩니다. 블록은 이름과 도움말 버튼으로 구성되어있고 마우스 드래그 기능을 사용해 화면 가운데에 배치할 수 있습니다.
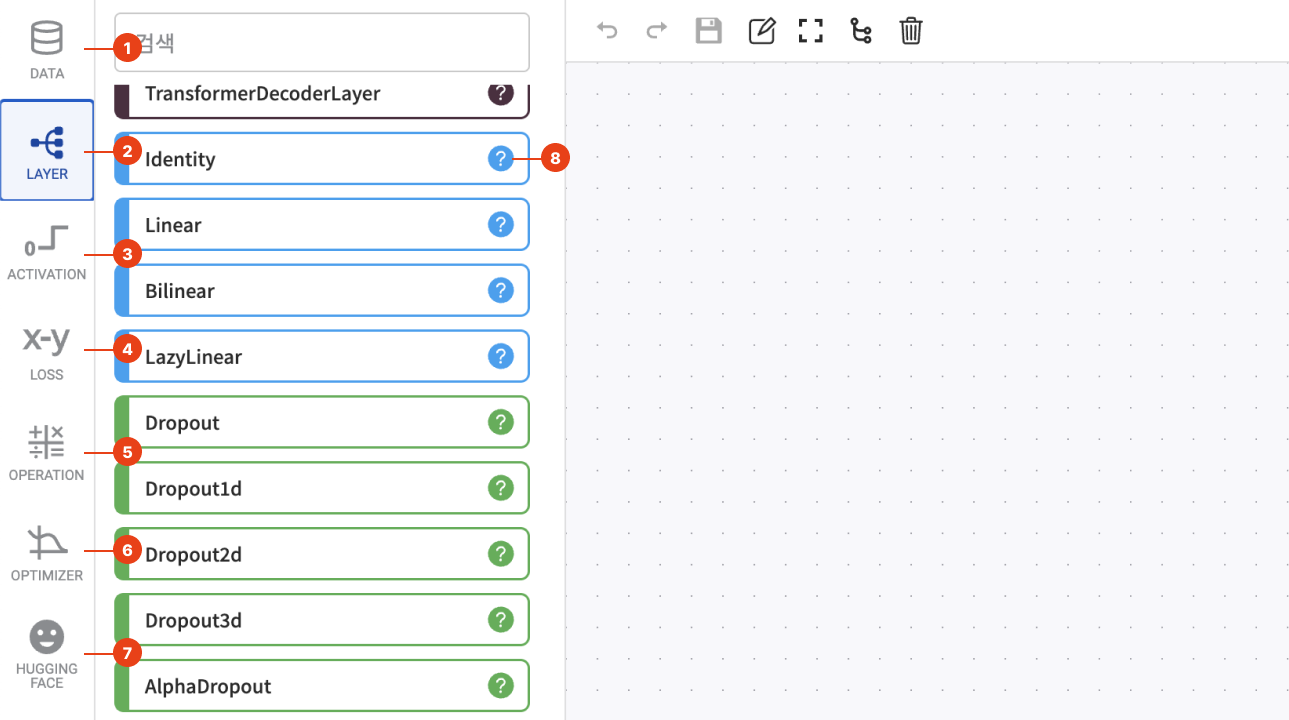
| 1 | Data | 사용 데이터에 맞는 블록을 선택해주세요. |
| 2 | Layer | 딥러닝 레이어 블록들입니다. |
| 3 | Activation | 활성화 함수 블록들입니다. |
| 4 | Loss | 손실 함수 블록들입니다. |
| 5 | Operation | 각종 수학 연산을 위한 블록들입니다. |
| 6 | Optimizer | 옵티마이저 블록들입니다. |
| 7 | Huggingface | Huggingface 라이브러리에서 제공하는 기능의 블록들입니다. |
| 8 | 블록 도움말 버튼 | 블록에 대한 상세 정보를 확인할 수 있습니다. 버튼 클릭 시 프로젝트에 해당하는 프레임워크의 공식 문서를 새 창으로 띄웁니다. |
가운데 영역에서 블록을 배치하고 연결해 모델을 개발할 수 있습니다. 데이터 블록의 경우 데이터 설정을 통해 입력 데이터를 전처리 할 수 있습니다. 이 외의 블록에 대해 파라미터(parameter) 값을 입력할 수 있습니다. 상단에는 실행 취소, 메모, 화면 가운데 맞추기 등 편의성 기능을 사용할 수 있는 버튼들이 있습니다.
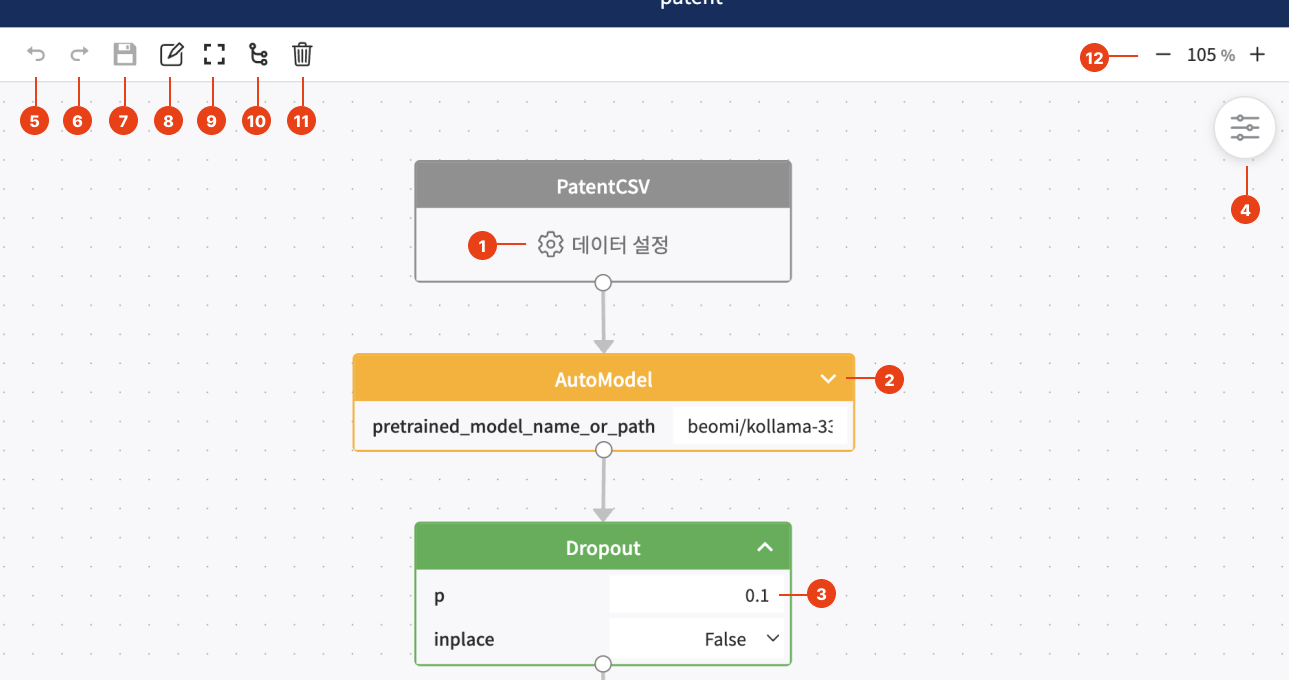
| 1 | 데이터 설정 | 입력 데이터에 대한 전처리를 할 수 있습니다. 자세한 설명은 다음을 참고해주세요. 데이터 설정하기 |
| 2 | 파라미터 (parameter) 열기/닫기 버튼 | 기본적으로 닫기 상태이며, 닫기 상태일때는 기본값이 없는 파라미터를 보여줍니다. 열기 상태일때는 모든 파라미터가 보여집니다. |
| 3 | 파라미터 (parameter) | 블록에 대해 입력받아야 할 파라미터입니다. 필수로 입력해야 하는 파라미터의 경우 값이 비어있으면 의도하지 않은 코드가 생성될 수 있습니다. |
| 4 | Hyper parameter 설정 버튼 | 버튼 클릭시 프로젝트를 만들때 입력했던 Hyper parameter 설정창을 열며, 내용을 변경할 수 있습니다. |
| 5 | 실행 취소 | 가장 마지막에 했던 작업을 취소하고 이전 상태로 되돌립니다. Ctrl+Z키를 눌러 사용할 수도 있습니다. |
| 6 | 되돌리기 | 실행 취소한 작업을 되돌립니다. 실행 취소하기 전의 상태로 되돌립니다. Ctrl+Shift+Z키를 눌러 사용할 수도 있습니다. |
| 7 | 저장 및 코드 생성 | 모델 변경 사항을 저장하고 소스 코드를 생성합니다. 생성된 소스코드는 페이지 우측 영역에 반영됩니다. Ctrl+S키를 눌러 사용할 수도 있습니다. |
| 8 | 메모 | 클릭 시 메모지가 추가됩니다. |
| 9 | 화면 가운데 맞춤 | 클릭 시 화면이 가운데에 맞추어집니다. |
| 10 | 블록 정렬 | 클릭 시 연결된 순서에 따라 블록이 정렬됩니다. 이때 블록 그룹이 설정되어 있다면 그룹이 해제됩니다. |
| 11 | 전체 삭제 | 클릭 시 모델을 구성하는 모든 요소가 삭제됩니다. |
| 12 | 줌 (Zoom) | 기본적으로 마우스 휠 (Wheel)을 사용해 줌 기능을 사용할 수 있고, 해당 버튼과 입력값을 통해 보다 세밀하게 설정이 가능합니다. |
우측 영역에서 개발한 모델에 대한 소스코드를 확인할 수 있습니다. 상단에는 생성된 소스코드를 실행하는 버튼, 코드 복사 버튼, 코드 다운로드 버튼으로 구성되어 있습니다.
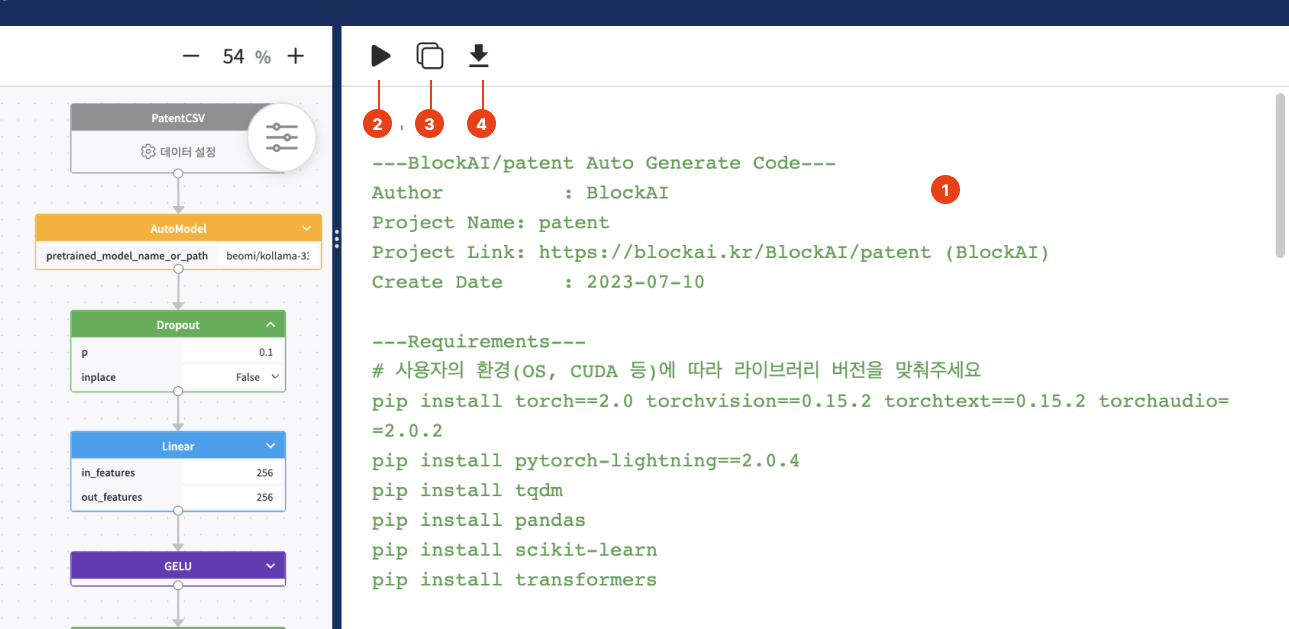
| 1 | 소스코드 | 화면 가운데 영역에서 개발한 모델을 저장하면 해당 영역에 소스코드가 생성됩니다. |
| 2 | 소스코드 실행 | 클릭 시 소스코드가 실행됩니다. |
| 3 | 소스코드 복사 | 클릭 시 생성된 소스코드가 클립보드에 복사됩니다. |
| 3 | 다운로드 | 소스코드를 포함한 프로젝트 폴더구조 전체 혹은 .py 확장자의 Python 소스코드, .ipynb 확장자의 Jupyter Notebook 소스코드를 선택해서 다운받을 수 있습니다. |
모델 개발하기
마우스 드래그 & 드랍 기능으로 블록을 배치, 연결하고 입력 데이터 전처리를 설정해 모델을 개발할 수 있습니다. 개발한 모델을 저장하면 소스코드로 변환되고 복사 및 다운로드 기능을 통해 자유롭게 사용할 수 있습니다.
블록 배치하기
화면 좌측에서 사용할 블록을 선택해 마우스로 드래그 한 후, 화면 중앙의 캔버스에 블록을 올려놓습니다. 캔버스 위에 올려진 블록은 마우스 드래그를 통해 움직일 수 있고, Shift를 누른채로 마우스 드래그를 하면 다중 선택이 가능합니다.
데이터 설정하기
좌측 메뉴의 Data 탭에서 입력 데이터를 처리하는 데이터 블록을 가져올 수 있습니다. 데이터 블록은 CSV, Image 블록이 있으며 캔버스에 배치 후 데이터 설정 버튼을 눌러 입력 데이터에 대한 전처리 설정을 해주어야 합니다.
CSV 데이터 설정
데이터 설정에 대한 각 입력값은 아래 그림과 함께 설명을 참고해 주세요.
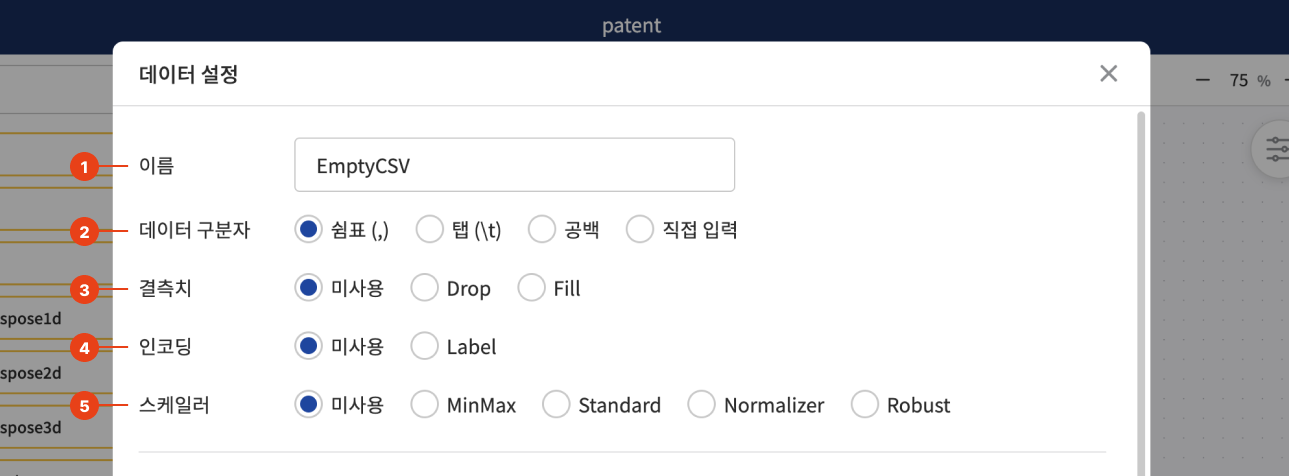
| 1 | 블록 이름 | 데이터 블록을 식별하기 위한 이름을 설정할 수 있습니다. |
| 2 | 데이터 구분자 | CSV파일에서 데이터를 구분하는 값을 선택해주세요. |
| 3 | 결측치 | 결측치 처리가 필요할 경우 삭제(Drop)할지 특정 값으로 치환(Fill)할지 선택해주세요. |
| 4 | 인코딩 | 카테고리 데이터의 인코딩이 필요할 경우 선택해주세요. |
| 5 | 스케일러 | 숫자 데이터의 스케일링이 필요할 경우 선택해주세요(Scikit-learn 라이브러리를 활용합니다.). |
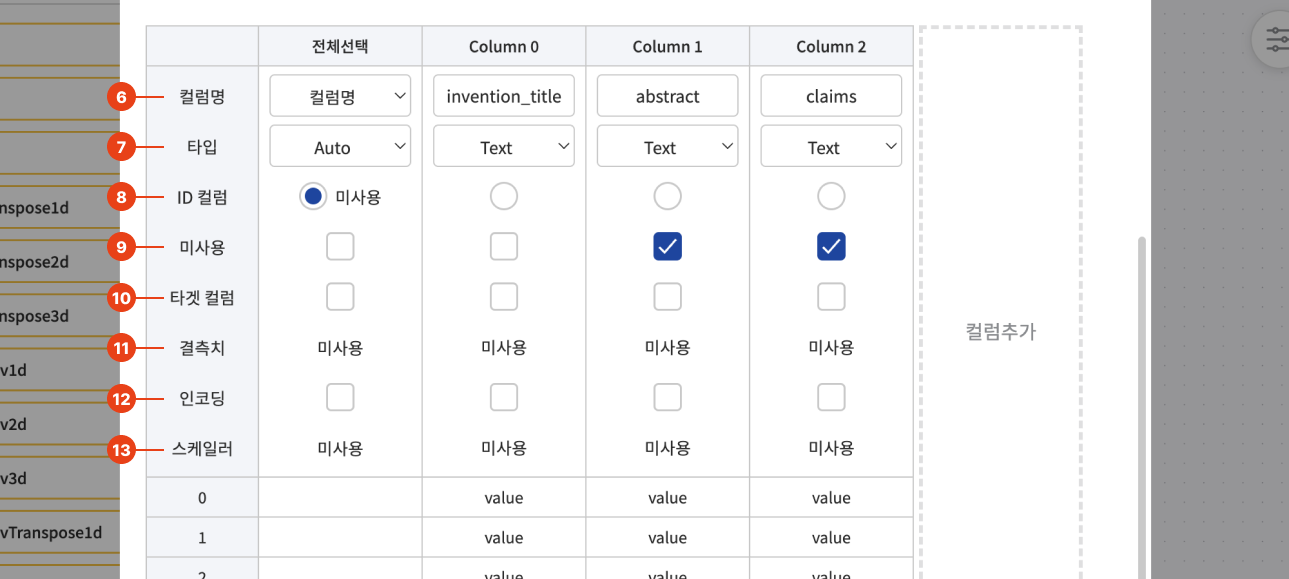
| 6 | 컬럼명 | CSV 파일에 컬럼명이 있다면 입력해주시고, 없다면 index를 선택해주세요. |
| 7 | 타입 | 각 컬럼의 타입을 선택해주세요, Huggingface를 사용하는 Text 컬럼일 경우 정확하게 선택해주세요. |
| 8 | ID 컬럼 | ID컬럼(index 컬럼)이 있다면 선택해주세요. |
| 9 | 미사용 | 사용하지 않는 컬럼이 있다면 선택해주세요(해당 컬럼을 삭제하는 코드가 추가됩니다.). |
| 10 | 타겟 컬럼 | 타겟(정답) 컬럼을 선택해주세요. |
| 11 | 결측치 | 결측치 처리가 필요한 컬럼을 선택해주세요. |
| 12 | 인코딩 | 인코딩 처리가 필요한 컬럼을 선택해주세요. |
| 13 | 스케일러 | 스케일링 처리가 필요한 컬럼을 선택해주세요. |
Image 데이터 설정
전처리 함수를 선택하고 추가해 학습 입력 이미지, 평가 입력 이미지, 학습 출력 이미지(정답 형식을 입력 데이터로 설정한 경우)를 전처리 할 수 있습니다. 데이터 설정에 대한 각 입력값은 아래 그림과 함께 설명을 참고해 주세요.
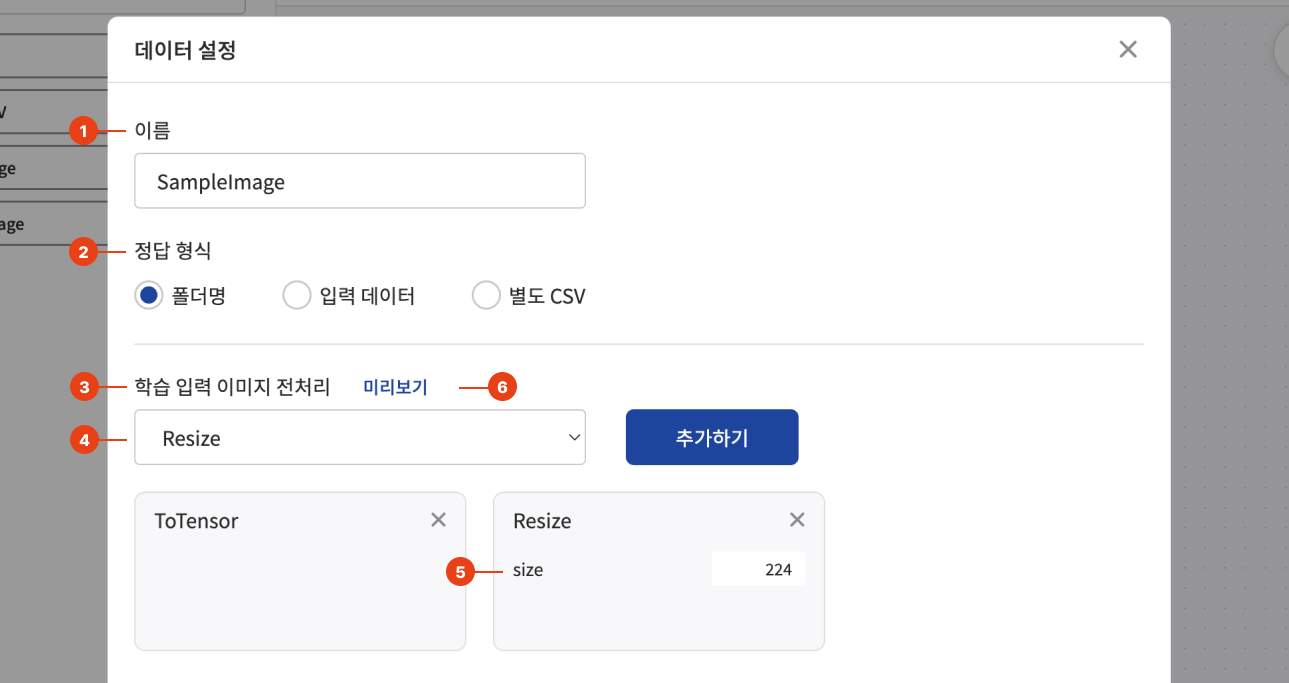
| 1 | 블록 이름 | 데이터 블록을 식별하기 위한 이름을 설정할 수 있습니다. |
| 2 | 정답 형식 | 폴더명 - 이미지 데이터가 들어있는 폴더의 이름이 타겟(정답)일 경우 입력 데이터 - 입력된 이미지 데이터를 타겟(정답)으로 사용하는 경우 별도 CSV - 별도의 CSV를 통해 타겟(정답)을 사용하는 경우로 CSV 파일명을 입력해주어야 합니다. |
| 3 | 학습 입력 이미지 전처리 | |
| 4 | 전처리 함수 선택 | 전처리 함수를 선택해 추가하기를 누르면 하단에 함수 블록이 생성됩니다. |
| 5 | 함수 파라미터 (Parameter) | 전처리 함수의 파라미터를 입력합니다. |
| 6 | 전처리 결과 미리보기 | 추가한 전처리 함수를 적용했을 때의 결과를 확인할 수 있습니다. |
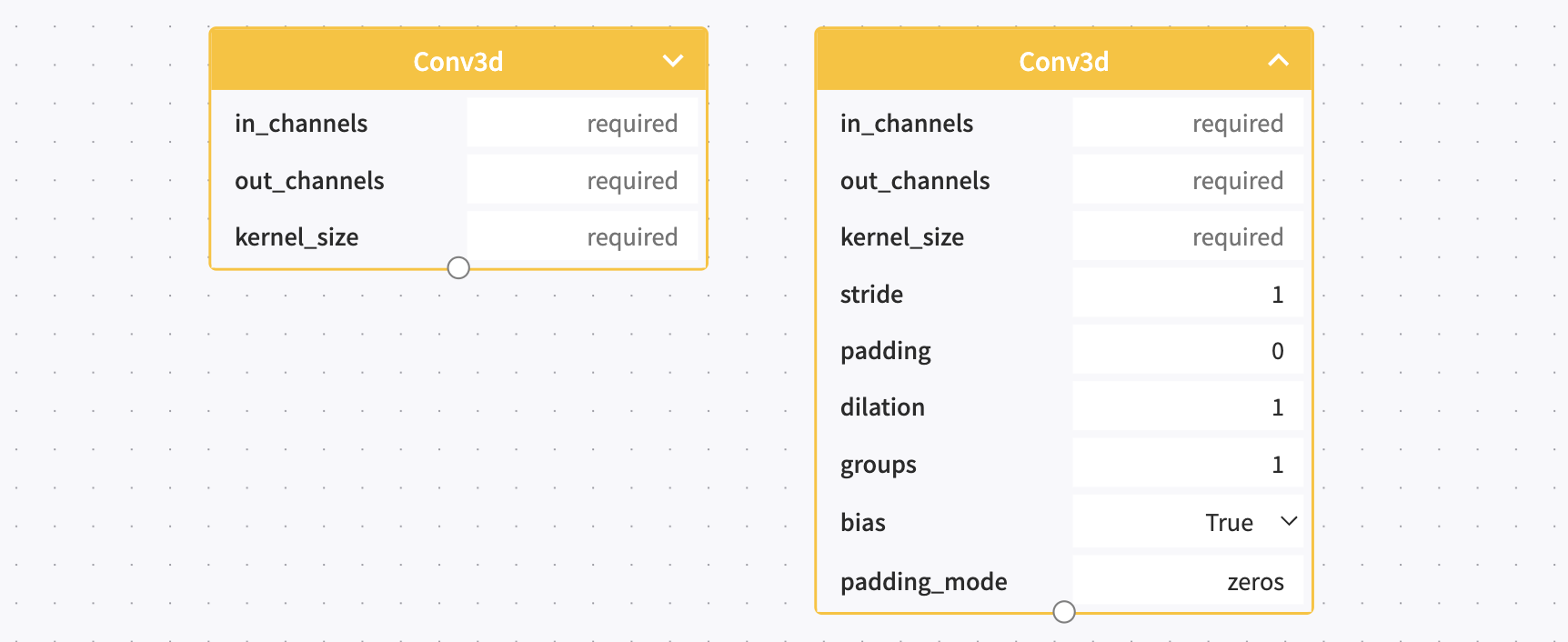
블록 파라미터 입력
좌측 메뉴에서 가져온 블록에 대해 파라미터 (Parameter)를 정확히 입력해주어야 원하는 소스코드를 얻을 수 있습니다. 기본 값이 없어 값을 사용자로부터 입력받아야 하는 파라미터들을 보여주고 있으며, 우측 상단의 화살표 버튼을 클릭하면 아래 그림의 우측 블록과 같이 입력 받을 수 있는 모든 파라미터를 보여줍니다.
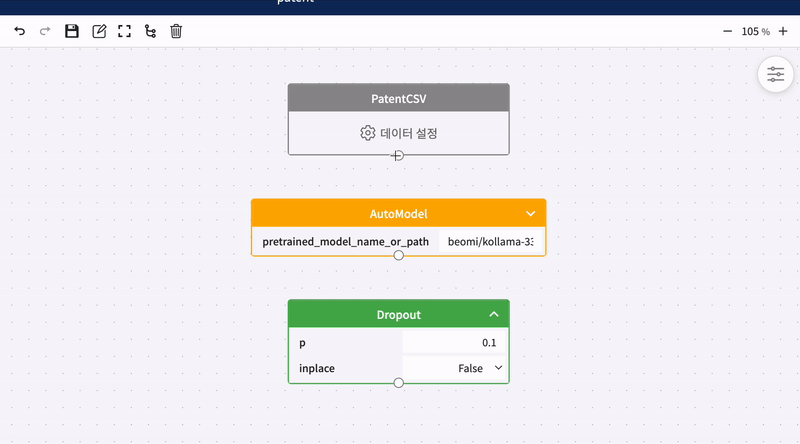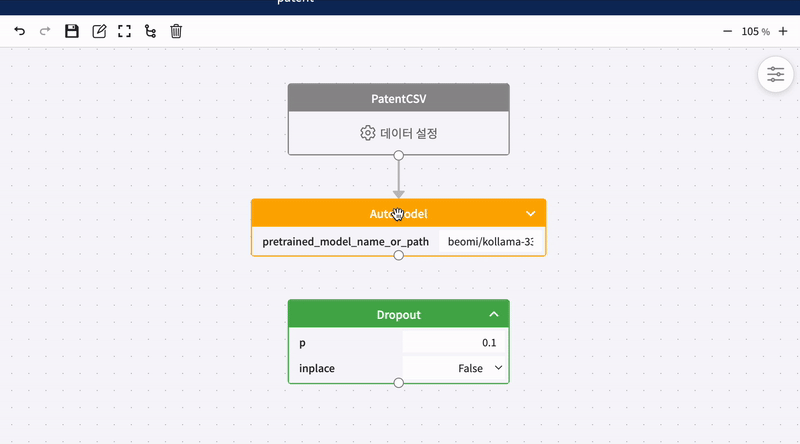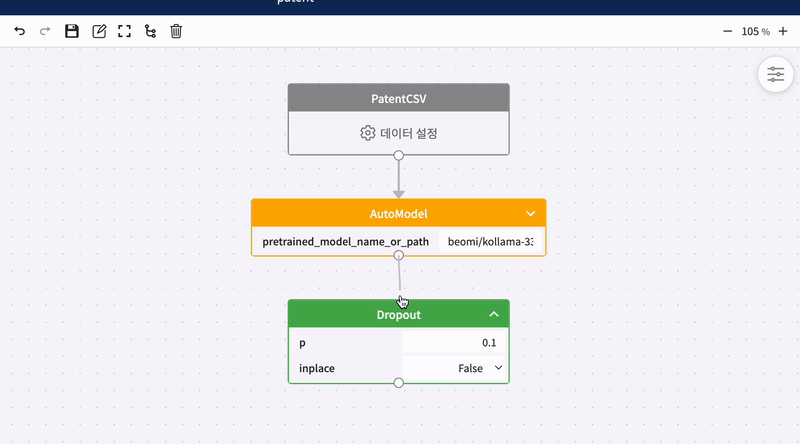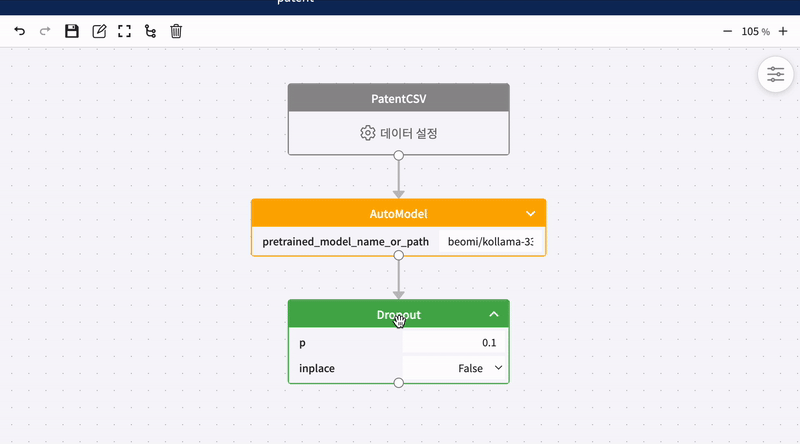
블록 연결하기
캔버스 위에 놓여진 모든 블록은 하단의 동그라미 버튼을 드래그하면 연결선을 그릴 수 있습니다. 연결선을 그리고 있는 상태일 때 데이터 블록을 제외한 모든 블록에 마우스를 가져다 대면 블록과 블록을 연결할 수 있습니다.
저장 및 코드 생성하기
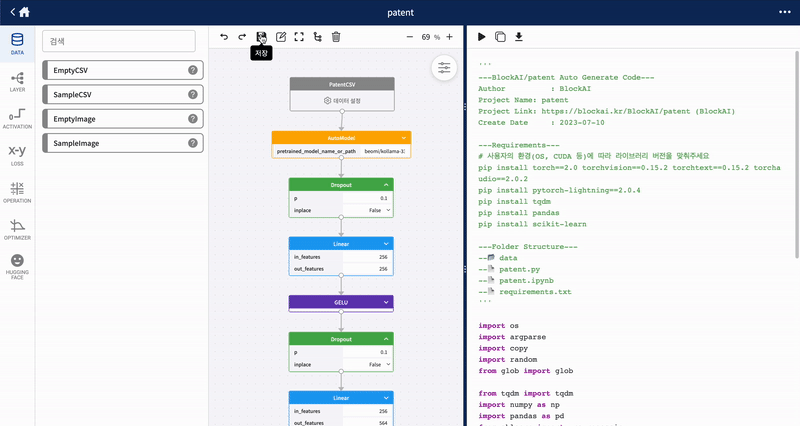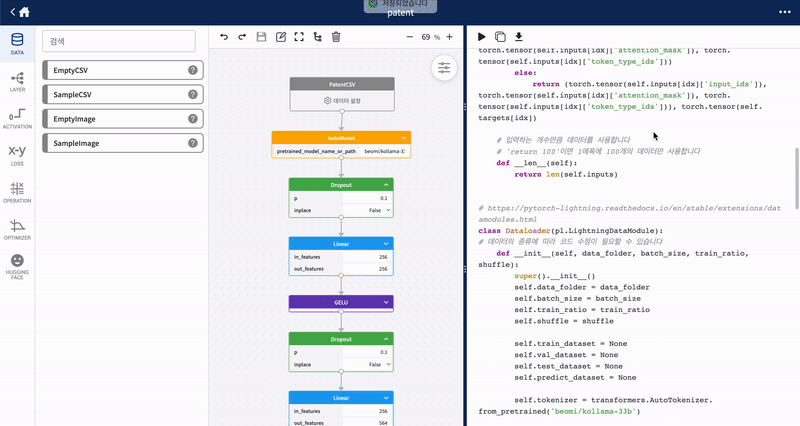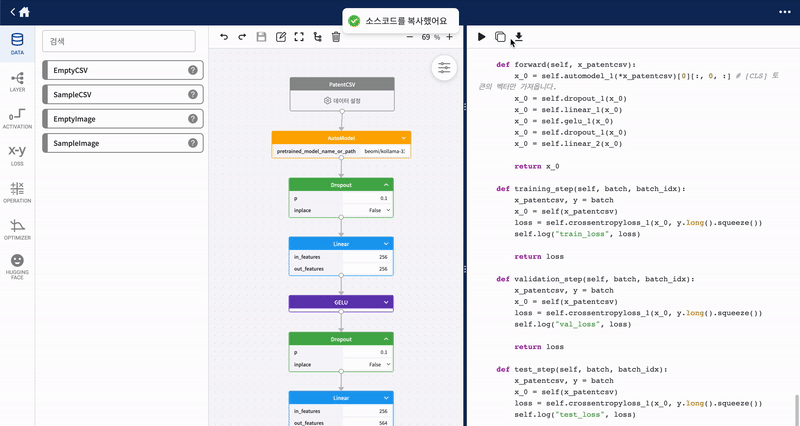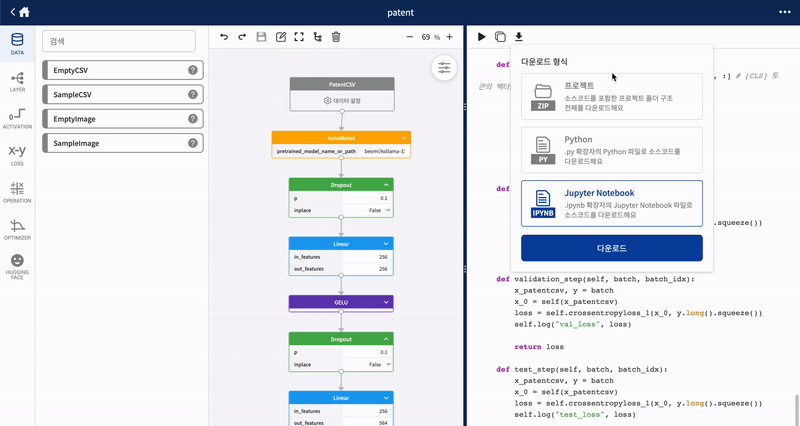
데이터 및 블록 파라미터 설정, 블록 연결로 모델 개발이 완성되면 저장 버튼을 눌러 저장과 함께 코드가 생성되어 화면 우측에 반영됩니다. 생성된 코드는 화면 우측 상단의 모델 실행, 소스코드 복사, 소스코드 다운로드 버튼을 눌러 다양하게 활용할 수 있습니다.
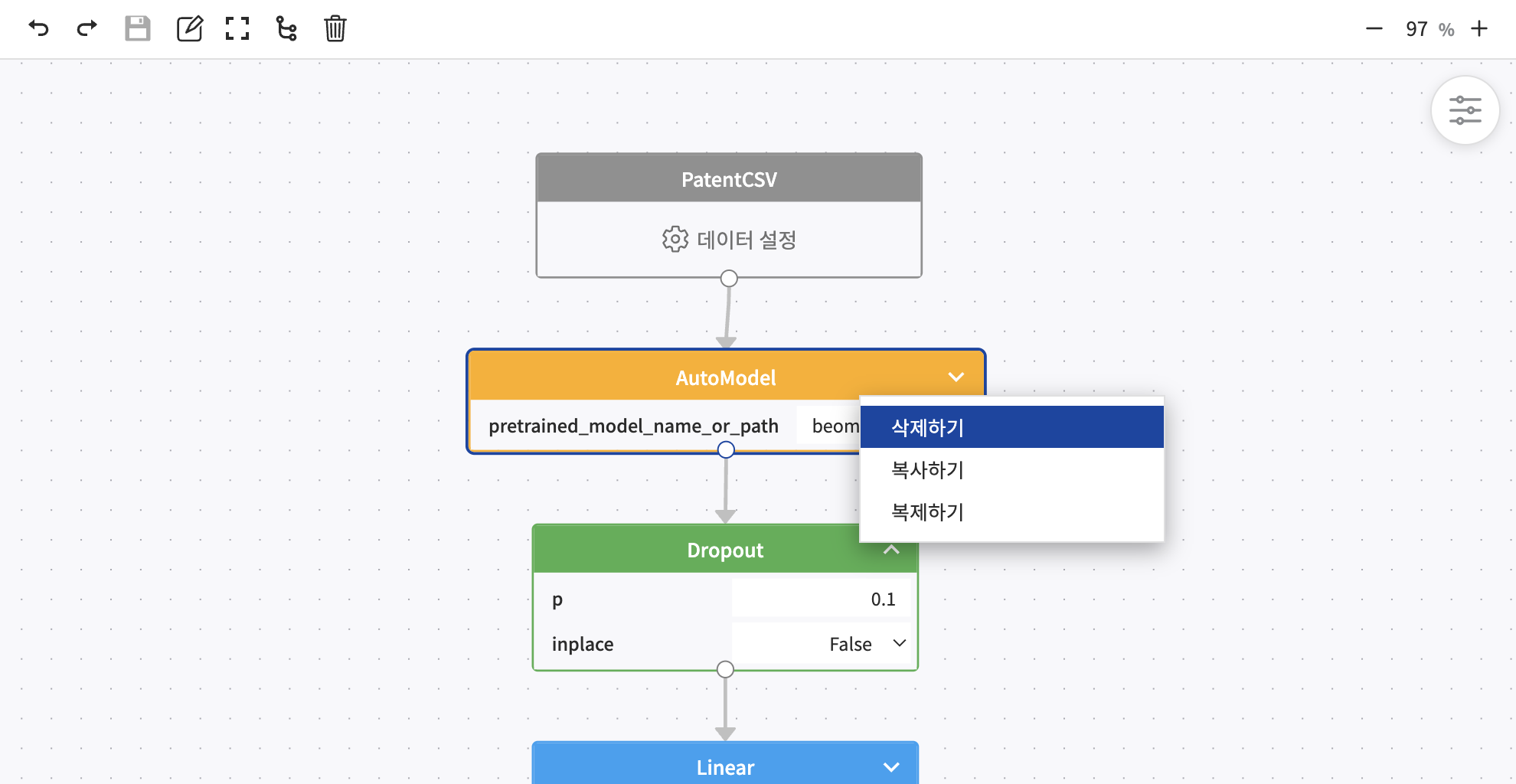
블록 및 연결선 삭제하기
캔버스에 올려진 블록 및 연결선 위에 마우스를 올려두고 마우스 오른쪽 클릭을 하면 메뉴가 등장합니다. 메뉴에서 삭제하기를 클릭하면 블록 및 연결선이 삭제됩니다.